| ||||
|
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Tip for sending me email: My email filters are super aggressive and I no longer look at the spam mailbox. If you include the phrase "embedded muse" in the subject line your email will wend its weighty way to me. I'm off sailing for a couple of months so may be very slow in replying to email. Alas, it appears my favorite metrics tool is no longer available. Msquaredtechnologies's RSM is/was a $200 comprehensive program that analyzed even huge code bases. I even ran it against Linux once. Though the web site is still there it sports broken links, the ordering page does not work and they don't respond to email. An alternative is the free Sourcemonitor. |
||||
| Quotes and Thoughts | ||||
|
Keep requirements workshops and review teams small. A large group of people cannot agree to leave a burning room, let alone agree on exactly how some requirement should be worded. Karl Wiegers |
||||
| Tools and Tips | ||||
|
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. |
||||
| Linux Kernel Programming | ||||
|
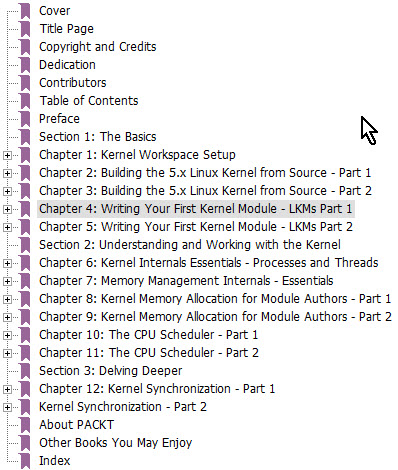
Kaiwan N Billimoria has a new book out named Linux Kernel Programming, and it's a heck of a volume. At 741 pages it is very comprehensive. I haven't read the entire book; rather I've surfed through it, so this is not a review. The book is very well-written and Kaiwan makes working on the kernel crystal clear, starting with basic concepts and giving detailed examples. If you've never built the kernel he goes through the process step by step. Probably the best way to get a flavor is the table of contents:
You can get it from Amazon for $44.99. But wait, there's more! His follow-on book Linux Kernel Programming Part 2 - Char Device Drivers and Kernel Synchronization is about creating user-kernel interfaces, work with peripheral I/O, and handle hardware interrupts. It's $34.99 from Amazon, and an e-version may be free from Packt. This is a 450 page tome that delves even deeper into the subject. Bottom line: If I were working on the kernel, I'd immediately buy these two books. |
||||
| RAM Tests on the Fly | ||||
|
In 1975 MITS shocked the techie world when they introduced the Altair computer for $400 (in kit form), the same price Intel was charging for the machine's 8080 CPU. That's $2200 in today's dollars, which would buy a pretty nifty Dell. The Altair included neither keyboard, nor monitor, had only 256 bytes (that's not a typo) of RAM, and no mass storage. I'd rather have the Dell. The 256 bytes of RAM were pretty limiting, so the company offered a board with 4k of DRAM for $195 (also in kit form). These boards were simply horrible and offered reliably unreliable performance. Their poor design insured they'd drop bits randomly and frequently. Though MITS eventually went out of business the computer revolution they helped midwife grew furiously. As did our demand for more and cheaper memory. Intel produced the 2107 DRAM which stored 16k bits of data. But users reported unreliable operation which by 1978 was traced to the radioactive decay of particles in the chip's packaging material. It turns out that the company built a new fab on the Green River in Colorado, downstream of an abandoned uranium mine. The water used to manufacture the ceramic packages was contaminated with trace amounts of radioactivity. The previous generation of DRAM had a storage charge of about 4 million electrons per bit; the 2107, using smaller geometry, reduced that to one million, about the energy from an alpha particle. Polonium 210 occurs naturally in well water and as a decay of product of radon gas. Yet far less than one part per billion, if it were in a DRAM package, would cause several bit flips per minute. This level of radioactivity is virtually undetectable, and led to a crisis at an IBM fab in 1987 when chips were experiencing occasionally random bit flips due to polonium contamination. Many months of work finally determined that one container of nitric acid was slightly "hot." The vendor's bottle cleaning machine had a small leak that occasionally emitted minute bits of Po210. The story of tracing the source of the contamination reads like a detective thriller (IBM Experiments is Soft Fails in Computer Electronics, J. F. Ziegler et al, IBM Journal of Research Development volume 40 number 1, January 1996). Cosmic rays, too, can flip logic bits, and it's almost impossible to build effective shielding against these high-energy particles. The atmosphere offers the inadequate equivalent of 13 feet of concrete shielding. Experiments in 1984 showed that memory devices had twice as many soft errors in Denver than at sea level. A 2004 paper (Soft Errors in Electronic Memory by Tezzaron Semiconductor) shows that because DRAMs have shrunk faster than the charge per cell has gone down, today's parts are less vulnerable to cosmic ray effects than those from years ago. But these energetic particles from deep space can create havoc in new dense SRAMs and FPGAs. The paper claims a system with one GB of SRAM can expect a soft error every two weeks! According to an article in EETimes which is no longer available (why do magazines change URLs willy-nilly?) a particle with as little as a 10 femtocoulomb charge has enough energy to flip an SRAM bit; a decade earlier the larger cells needed five times more energy. Old-timers remember that most PCs had 9 bit memory configurations, with the ninth reserved for parity to capture DRAM errors. That's ancient history on the desktop, though servers often use parity or error-correcting logic to provide the high degree of reliability users expect. We've long used RAM tests of various stripes to find hard errors - bad wiring, failed chips, and the like. But soft errors are more problematic. Some systems must run continuous RAM tests as the application executes, sometimes to find hard errors - actual hardware failures - that occur over time, and sometimes to identify soft errors. Are these tests valuable? One wonders. Any sort of error in the stack space will immediately cause the system to crash unpredictably. A hardware flaw, say an address or data line failure, takes out big chunks of memory all at once. Recovery might be impossible, though I've heard claims that memory failures in the deep-space Pioneer probe were "fixed" by modifying the code to avoid those bad locations. But for better or worse, if your requirements demand on-the-fly RAM tests, how will you conduct these without altering critical variables and code? Since hard and soft errors manifest themselves in completely different ways the tests for these problems are very different. Let's look at hard errors first. Before designing a test it's wise to consider exactly what kinds of failures may occur. On-chip RAM won't suffer from mechanical failures (such problems would probably take out the entire device), but off-chip memory uses a sometimes very complex net of wiring and circuitry. Wires break; socketed chips rattle loose or corrosion creates open circuits; and chips fail. Rarely a single or small group of bits fail inside a particular memory device, but today such problems are hardly ever seen. It probably, except in systems that have the most stringent reliability requirements, makes sense to not look for single bit failures, as such tests are very slow. Most likely the system will crash long before any test elicits the problem. Pattern sensitivity is another failure mode that used to be common, but which has all-but-disappeared. The "walking ones" test was devised to find such problems, but is computationally expensive and destroys the contents of large swaths of memory. There's little reason to run such a test now that the problem has essentially disappeared. So the tests should look for dead chips and bad connections. If there's external memory circuitry, say bus drivers, decoders, and the like, any problem those parts experience will appear as complete chip failures or bad connections. I want to draw a distinction between actually testing RAM to ensure that it's functional, and that of insuring the contents of memory are consistent, or have reasonable values. The latter we'll look at when considering soft errors next month. Traditional memory tests break down when running in parallel with an executing application. We can't blithely fill RAM with a pattern that overwrites variables, stacks and maybe even the application code. On-the-fly RAM tests must cautiously poke at just a few locations at a time, and then restore the contents of these values. Unless there's some a priori information that the locations aren't in use, we'll have to stop the application code for a moment while conducting each step. Thus, the test runs sporadically, stealing occasional cycles from the CPU to check just a few locations at a time. In simpler systems that constantly cycle through a main loop, it's probably best to stick a bit of code in the loop that checks a few locations and then continues on with other, more important activities. A static variable holds the last address tested so the code snippet knows where to pick up when it runs again. Alternatively run a periodic interrupt whose ISR checks a few locations and then returns. In a multitasking system a low-priority task can do the same sort of thing. If any sort of preemption is happening, turn interrupts off so the test itself can't be interrupted with RAM in a perhaps unstable state. Pause DMA controllers as well and shared memory accesses. But what does the test look like? The usual approach is to stuff 0x5555 in a location, verify it, and then repeat using 0xAAAA. That checks exactly nothing. Snip an address line with wire cutters: the test will pass. Nothing in the test proves that the byte was written to the correct address. Instead, let's craft an algorithm that checks address and data lines. For instance: 1 bool test_ram(){
2 unsigned int save_lo, save_hi;
3 bool error = FALSE;
4 static unsigned int test_data=0;
5 static unsigned long *address = START_ADDRESS;
6 static unsigned int offset;
7 push_intr_state(); 8 disable_interrupts(); 9 save_lo = *address; 10 for(offset=1; offset<=0x8000; offset=offset<<1){
11 save_hi = *(address+offset);
12 *address = test_data;
13 *(address+offset) = ~test_data;
14 if(*address != test_data)error=TRUE;
15 if(*(address+offset) != ~test_data)error=TRUE;
16 *(address+offset) = save_hi;
17 test_data+=1;
18 }
19 *address = save_lo;
20 pop_intr_state();
21 return error;}
START_ADDRESS is the first location of RAM. In lines 9 and 11, and 16 and 19, we save and restore the RAM locations so that this function returns with memory unaltered. But the range from line 9 to 18 is a "critical section" – an interrupt that swaps system context while we're executing in this range may invoke another function that tries to access these same addresses. To prevent this line 8 disables interrupts (and be sure to shut down DMA, too, if that's running). Line 7 preserves the state of the interrupts; if test_ram() were invoked with them off we sure don't want to turn them enabled! Line 19 restores the interrupts to their pre-disabled state. If you can guarantee that test_ram() will be called with interrupts enabled, simplify by removing line 7 and changing 20 to a starkly minimal interrupt enable. The test itself is simplicity itself. It stuffs a value into the first location in RAM, and then, by shifting a bit and adding that to the base address, to other locations separated by an address line. This code is for a 64k space, and in 16 iterations it insures that the address, data, and chip select wiring is completely functional, as is the bulk functionality of the memory devices. To cut down interrupt latency, you can remove the loop and test one pair of locations per call. The code does not check for the uncommon problem of a few locations going bad inside a chip. If that's a concern construct another test that replaces lines 10 to 18 with: *address = 0x5555; if(*address != 0x5555)error=TRUE; *address = 0xAAAA; if(*address != 0xAAAA)error=TRUE; *address = save_lo; address+=1; ... which cycles every bit at every location, testing one address each time the routine is called. Despite my warning above, the 0x5555/0xAAAA pair works because the former test checked the system's wiring. There are a lot of caveats – don't program these in C, for instance, unless you can ensure the tests won't touch the stack. And the value of these tests is limited since address and data bus errors most likely will crash the system long before the test runs. But in some applications using banks of memory a wiring fault might affect just a small subsection of RAM. In other systems the on-going test is important, even if meaningless, to meet the promises some naïve fool in marketing printed on the product's brochure. More on this in the next Muse. |
||||
| The Great Chip Shortage of 2021 | ||||
|
Much has been written about the global chip shortage, which is so severe it's impacting sales of new cars. Gartner is predicting that the shortage will last until Q2 2022 and beyond; apparantly some are paying 3X normal prices today. I assumed the parts in short supply would be bigger devices like SoCs and display controllers, as other reports suggest the automotive people canceled orders due to the pandemic last year, and the semi houses diverted to making SoCs et al for mobile devices. Turns out power management parts, MCUs and other parts made on older fabs (28 nm and bigger) are the primary problem. Opto, memory and discrete components aren't suffering as much. Forrester expects the shortage to last into 2023. Last year people were hoarding toilet paper; now Credit Suisse says we're doing the same with chips. Used car prices have spiked in reaction to the dearth of semiconductors. Gartner has some recommendations for dealing with the shortage, but I'm afraid these strategies won't help small- and mid-size manufacturers much. |
||||
| Failure of the Week | ||||
From Neil Peers:
Have you submitted a Failure of the Week? I'm getting a ton of these and yours was added to the queue. |
||||
| This Week's Cool Product | ||||
Mimicc is a mock generator and compiler for C and C++. Mimicc is first and foremost a tool for writing unit tests, and aims to remove the barriers commonly encountered by software developers writing tests for systems written in low-level power-tool programming languages. Mimicc was written with two guiding philosophies:
The tool is available for free from here. And do check out the user manual, which is unusually-well written and complete. Note: This section is about something I personally find cool, interesting or important and want to pass along to readers. It is not influenced by vendors. |
||||
| Jobs! | ||||
|
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
These jokes are archived here. Bob Snyder sent this all-too-appropriate "joke": The positive integers have gathered for the annual numbers convention. At the opening dinner, the number 13 stands up and says, "I'm the baddest number there is. Everyone's afraid of me." To that 666 gets up and says, "That's nothing. I'm in the Bible itself as the sign of the Apocalypse." The number 2020 slowly pushes back its chair, stands up, and says to its buddies, 'Hold my beer.' " |
||||
| About The Embedded Muse | ||||
|
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. can take now to improve firmware quality and decrease development time. |